
概要
半年ほど前に図書APIを用いて、ISBN番号から、書籍情報を取得する方法について調べました。
今回は、python から Selenium を介して、WEBブラウザを操作し、書籍情報を取得する方法を検討しました。ネット書店の検索ページを開き、ISBN番号設定、検索ボタンクリック、結果取得までの一連の操作を自動化します。
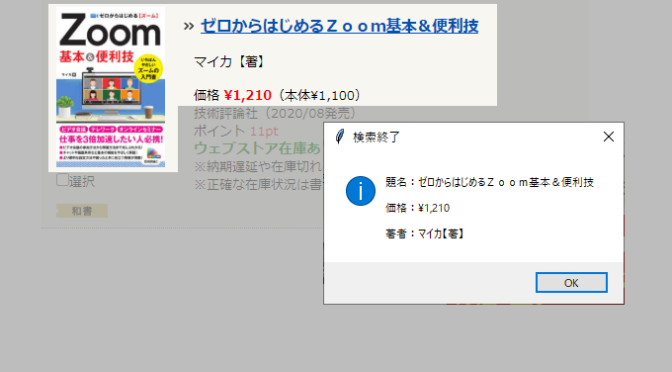
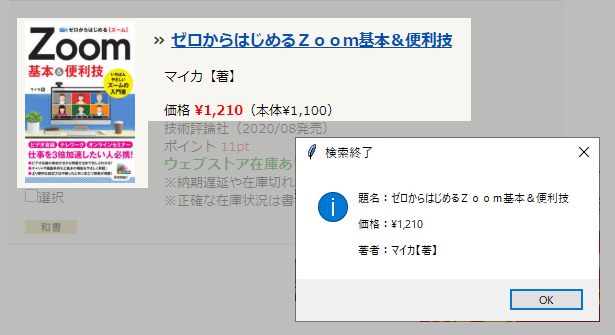
下図は検索の結果と取得したページの情報をメッセージボックスに出力した状況です。(対象サイトのURL等の記述は控えさせて頂きます。)
Beautiful Soup4 は、ブラウザを開かず指定したURLのHTML情報を取得・解析するので高速処理出来ます。一方、対象ページを直接URL指定できずに、何らかの操作によるページ移動が必要な場合には、‘Selenium’ 等での処理が有効と理解しています。
また、書籍APIとは異なり、様々な用途に利用できることが、 ‘Selenium’ の利点と思います。
処理の流れ
以下(1)~(3)の順に処理します。(2)(3)は自動処理です。
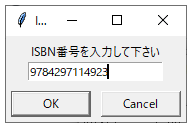
(1) ISBN番号入力
プログラム起動後、ISBN番号入力し、‘OK’をクリックします。
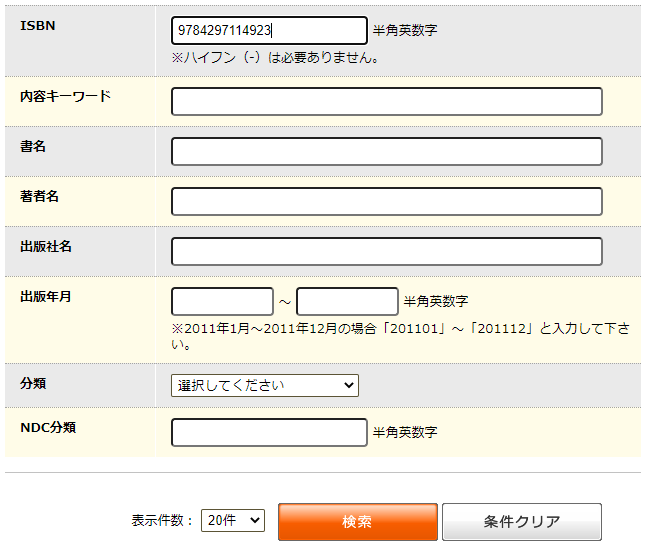
(2) 検索ページ ISBN設定、検索ボタンクリック
プログラムが 検索ページを開き、自動でISBN番号を設定後、検索ボタンをクリックします。
(3) 出力ページ移動後、結果出力
ブラウザが出力した検索結果のページから、本の題名,価格,著者情報を取得し、メッセージ出力します。
プログラム
先回GoogleChromeを操作する場合のドライバー設定等について記載していますので、設定の説明は省略します。
import time
import sys
import ctypes
import os
import tkinter as tk
from tkinter import messagebox
import tkinter.simpledialog as simpledialog
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.alert import Alert
root = tk.Tk()
root.attributes('-topmost',True)
root.withdraw()
root.lift()
root.focus_force()
isbn_no = simpledialog.askstring("ISBN入力","ISBN番号を入力して下さい")
try:
if len(isbn_no) != 13 :
isbn_no = "9784297114923"
except:
isbn_no = "9784297114923"
driver = webdriver.Chrome("./driver/chromedriver.exe")
#driver = webdriver.Edge(executable_path='./driver/msedgedriver.exe')
time.sleep(0.5)
driver.get('https://www.<省略>');
WebDriverWait(driver, 50).until(EC.presence_of_element_located((By.ID, '<省略>')))
driver.find_element_by_id("<省略>").send_keys(isbn_no)
driver.find_element_by_id("<省略>").click()
WebDriverWait(driver, 50).until(EC.presence_of_element_located((By.ID, '<省略>')))
book_name = driver.find_element_by_xpath('//*[@id="<省略>"]/form/div[1]/div/div[2]/h3/a').text
book_pric = driver.find_element_by_xpath('//*[@id="<省略>"]/form/div[1]/div/div[2]/div[3]/ul/li/span').text
book_wrtr = driver.find_element_by_xpath('//*[@id="<省略>"]/form/div[1]/div/div[2]/div[2]/p').text
messagebox.showinfo( "検索終了" , "題名:" + book_name + "\r\n\r\n価格:"+book_pric + "\r\n\r\n著者:" + book_wrtr )
プログラムについて簡単に説明します。
行17~21は、メッセージボックスを最前面にしたり、メッセージ出力時に意図しない枠(?)表示を消去する設定です。
行23でISBN番号入力メッセージボックスを表示します。行24~28はデバッグ対応で、入力不備でも値設定し処理を進めます。
行30はchromeドライバーを設定します。行30をコメントアウトし、行31のコメントを外すと、MicroSoftEdgeもブラウザーとして使用できます。(対応するドライバーをダウンロードし、パス指定が必要です。)
行34で検索ページを開き、行35はページが開くまで待ちます。行37でISBN番号を設定、行38は‘検索’ボタンをクリックします。
行40で検索結果が表示されるのを待って、行42~44でそれぞれ題名,価格,著者情報を取得し、結果を行46でメッセージ出力しています。
プログラムの中では次の様なメソッド(?)を用いて、HTMLの要素を見つけ、データ取得、データ設定、クリック等の処理を行っています。
・find_element_by_id
・find_element_by_name
・find_element_by_xpath
①~③に具体例を記載します。
①IDから要素をみつけ、データ設定する
driver.find_element_by_id(“<要素のID>”).send_keys(isbn_no)
②IDから要素をみつけ、クリックする
driver.find_element_by_id(” <要素のID> “).click()
③Xpath から要素を見つけ、値を取得する
book_name = driver.find_element_by_xpath(‘要素のXpath’).text
ID、Xpath 等について
今回のプログラム作成では、GoogleChromeのHTMLを調べる機能を使って、ID,Xpath等を調べました。
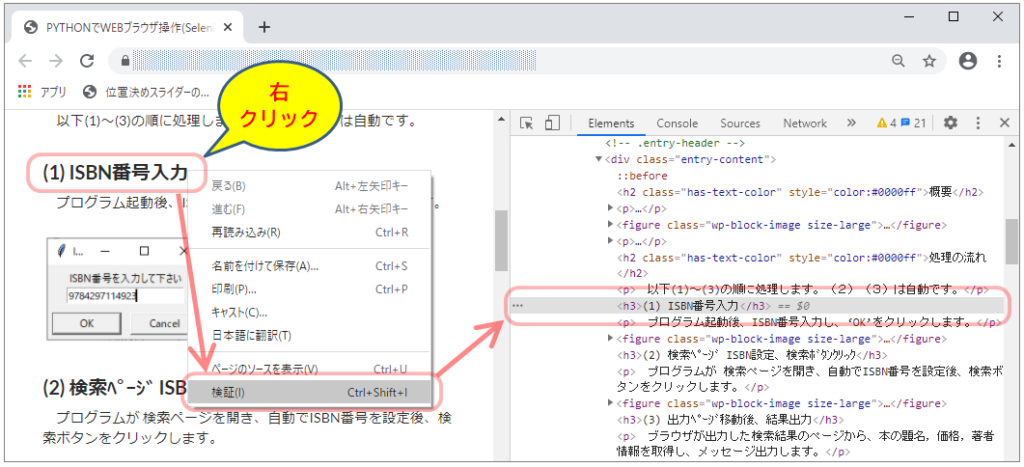
下図の通り、ブラウザの任意の位置で右クリックし、表示されるリストから “検証” を選択すると、HTMLコードが右側に表示されます。対象部がハイライトされ簡単に検索できることを知りました。(下図と今回のプログラム内容は全く関係ありません)
更に表示されたHTML上で右クリックし、“Copy” → “Copy XPath” を選択すると XPath がクリップボードにコピーされ、メモ帳等に貼り付けることが出来ます。
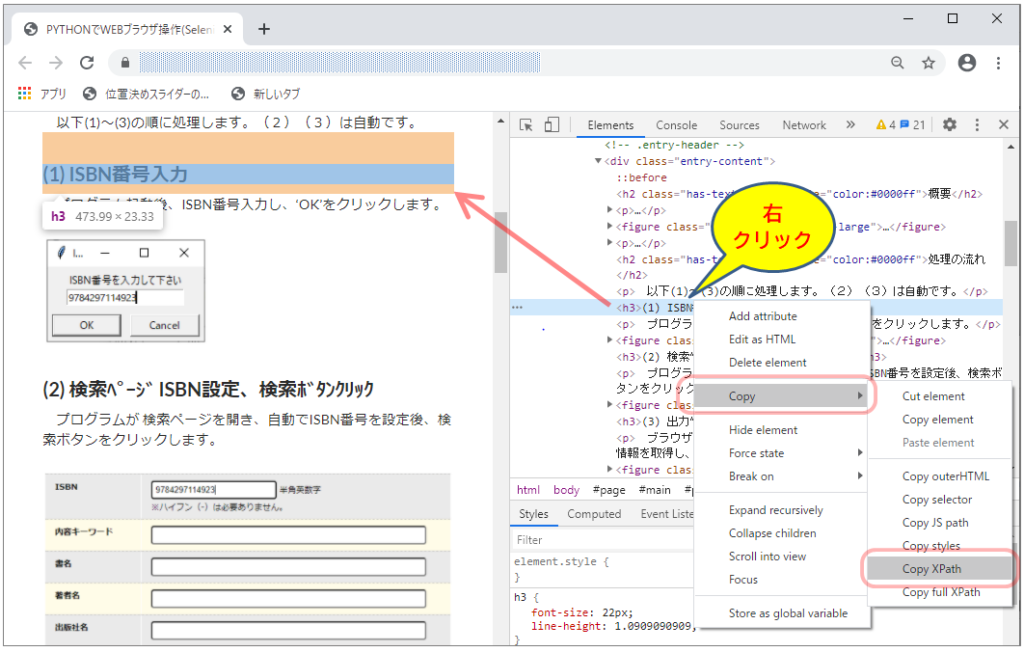
但し、今回は ISBN 番号と検索結果が1:1なので、あまり問題にはならないと思いますが、出力情報件数が変化するなど、HTMLの構成が変わる場合には注意が必要かもしれません。
まとめ
RPA(Robotic Process Automation )チック なことが出来るかもしれません。