
概要
前回投稿でラズパイに取り込んだ音声をFFT処理し、簡単な周波数解析を試みました。今回はそのプログラムを応用し、先ずいくつかの単調な電話着信音の特徴的周波数を調べます。次に調査結果をもとに、どの着信音が鳴っているか判定するプログラムを作成します。
尚、電話着信音として「OtoLogic」というサイトからフリー音声ファイルをダウンロードし、利用させて頂きました。
URL : 「OtoLogic」https://otologic.jp/free/se/phone02.html
着信音 周波数調査
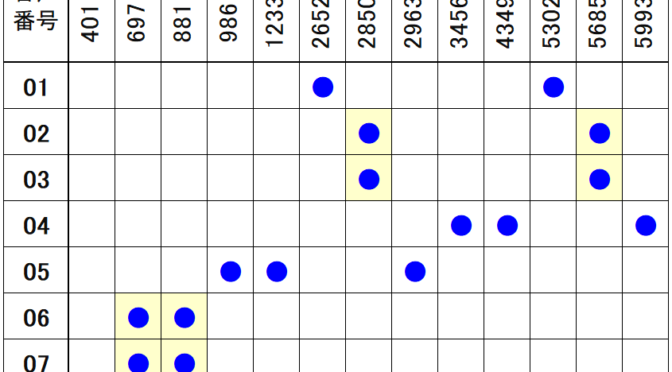
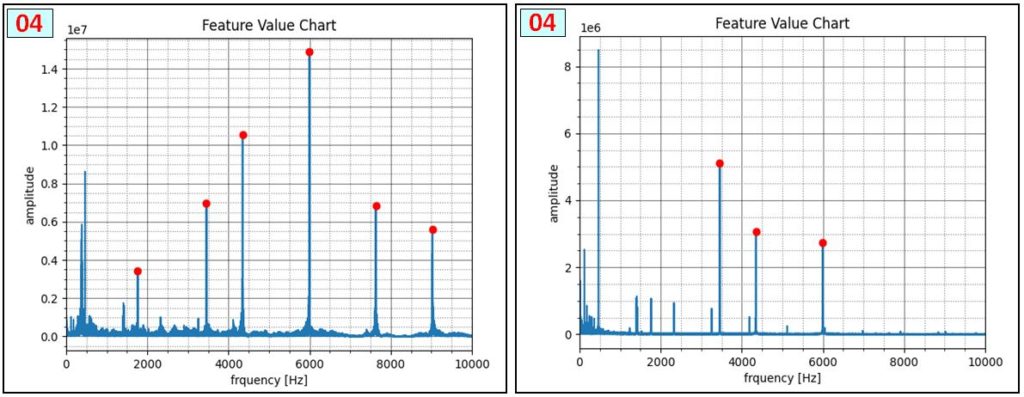
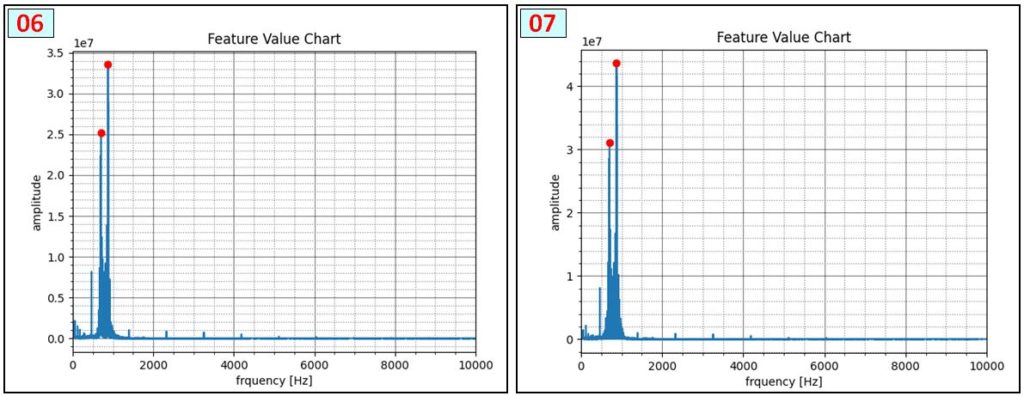
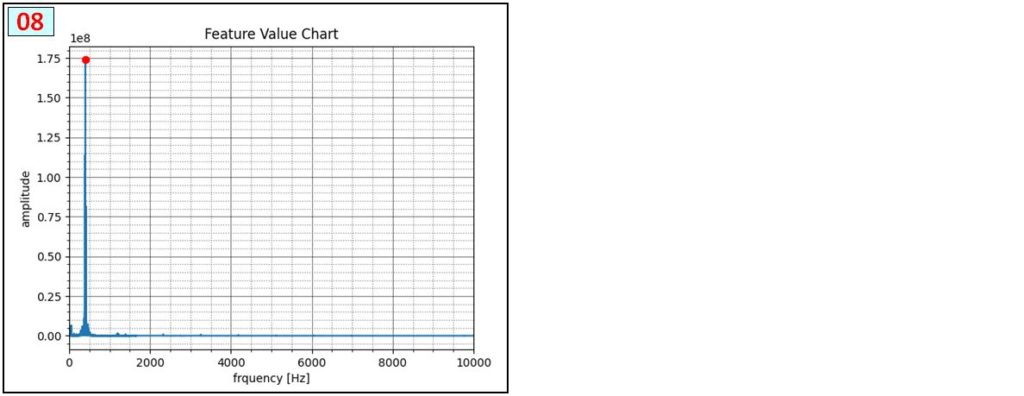
8種類の電話着信音について、次の表の通り特徴的周波数を調査しました。投稿最後の [資料] で各音声は確認できます。
プログラムで一定の大きさを超える周波数ピークを検出しました。雑音・測定タイミング・ピーク検出関数パラメータ等によってばらつきがあるので、約150~200 回 連続測定し、平均値(または最大・最小の中間値)にしています。音声 [02]と[03]、[06]と[07] は感覚的には異なる音なのですが、周波数成分は同じなので、このペアの識別は今回 断念しています。
1回の取得データ数 :102400 → 1024100/44100= 2.32 (sec/回) に1回 FFT処理
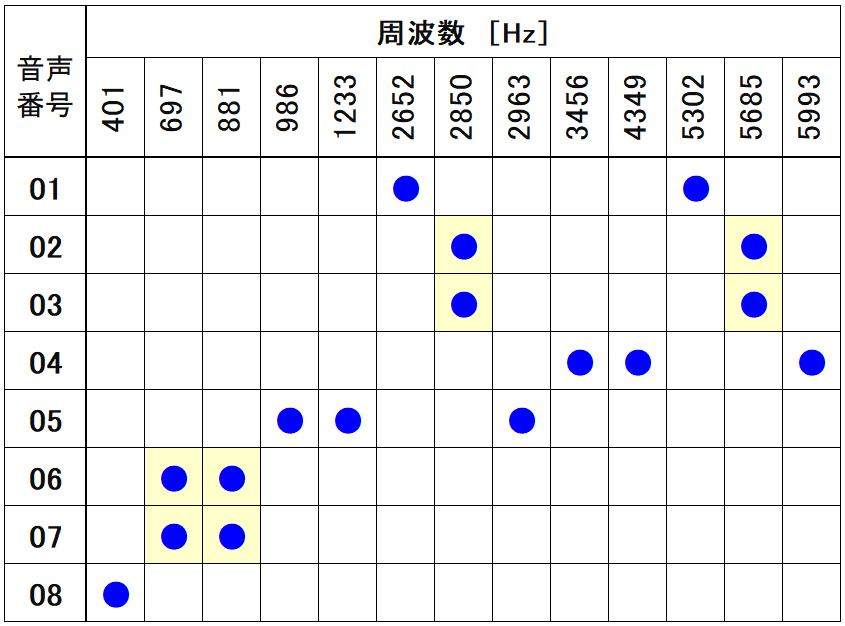
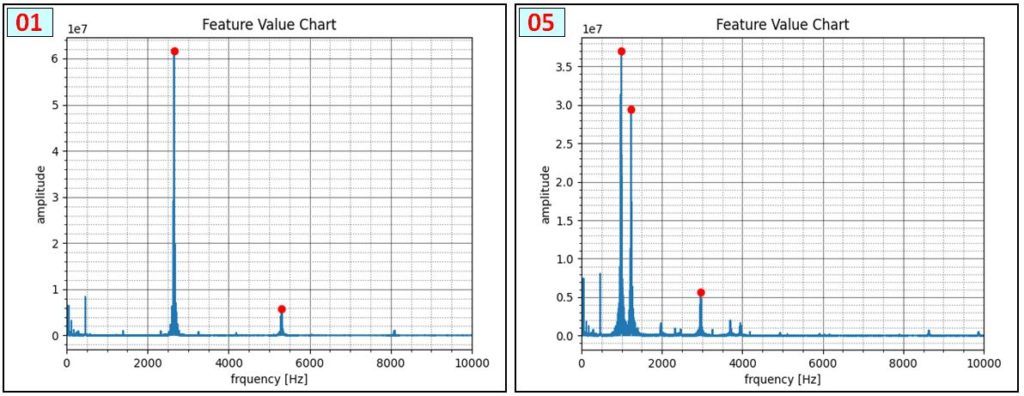
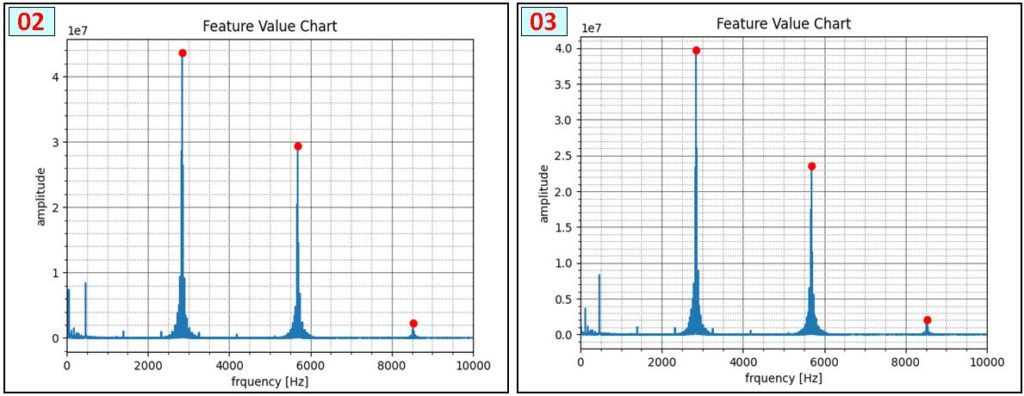
次の図は、各音声 [01~08] の周波数検出状況です。[04]は2画像ありますが、音声を連続的に繰り返し再生しても、測定開始タイミングで結果が大きく変わる例です。まったくピークが検出されない場合もあります。また、音声 [02]と[03]、[06]と[07] は同じ周波数成分で構成されていることを確認しました。厳密な解析をする場合は時系列的な変化を評価する必要性を認識しました。
結果は FFT処理毎にCSV形式でファイル出力しています。
着信音 周波数調査用プログラム
着信音 周波数調査用のプログラムです。前回投稿の周波数検出プログラムをベースに複数のピーク値検出、大きさ・周波数による絞り込み、結果CSVファイル出力、グラフ出力等の機能を追加・修正しています。
import pyaudio
import wave
import numpy as np
import matplotlib.pyplot as plt
import csv
import os
from scipy.signal import argrelmax
frm_dt = pyaudio.paInt16 # 16-bit resolution
chnl = 1 # 1 channel
s_rate = 44100 # 44.1kHz サンプリング周波数
N = 100 # chunk / s_rate = samp_time (sec)
chunk = 1024 * N # 2^12 一回の取得データ数 (1024*50/44100= 1.16 (sec), 1024*100/44100= 2.32 (sec))
dev_idx = 5 # デバイス番号(必須ではない?(優先度指定している為?))
no_idx_cnt = 0 # データ無し回数
pic_ser = 0 # 画像保存する時の連番
d_pth = '/home/pi/MySndTest/csv/' # データ保存ディレクトリパス
f_nam = '08' # ◆保存ファイル名◆
audio = pyaudio.PyAudio() # create pyaudio instantiation
# ストリーム作成
stream = audio.open(format = frm_dt , rate = s_rate , channels = chnl, input_device_index = dev_idx , \
input = True , frames_per_buffer = chunk )
# x軸( frquency )
wv_x1 = np.linspace(0, s_rate, chunk)
chnk_lmt = int(chunk/2) # FFT有効範囲考慮
wv_x2 = wv_x1[0:chnk_lmt]
print("Started")
# 音声取得/FFT処理
while True:
try:
# 音声データ取得
data = stream.read(chunk , exception_on_overflow=False )
ndarray = np.frombuffer(data, dtype='int16')
# y軸(FFT : amplitude)
wv_y1 = np.fft.fft(ndarray)
wv_y1 = np.abs(wv_y1)
wv_y2 = wv_y1[0:chnk_lmt]
peak_args = argrelmax(wv_y2,order=200) # ピーク検出(argrelmax:極大値インデックス ,order:次極大値判定範囲/間隔(最小:int 1))
# peak_args(index) >降順sort> peak_args_sort(index)に格納 # ◆未使用(参考)◆
f_peak = wv_y2[peak_args] # インデックスを強度値に変換
f_peak_argsort = f_peak.argsort()[::-1] # 強度降順並替(argsort:値昇順ソート(インデックス返す),[::-1]降順ソート時)
peak_args_sort = peak_args[0][f_peak_argsort] # 強度降順並替後のインデックス配列を指定し、強度降順配列を取得
# 対象を絞り込む
wv_x3 = wv_x2[peak_args]
wv_y3 = wv_y2[peak_args]
idx_1 = np.where((wv_y3 > 2 * 10**7) & (wv_x3 < 500) & (wv_x3 > 250))
idx_2 = np.where((wv_y3 > 2 * 10**6) & (wv_x3 >= 500))
idx_3 = np.append(idx_1, idx_2)
wv_x4 = wv_x3[idx_3]
wv_y4 = wv_y3[idx_3]
# データがある時、CSVファイルに書き込む
if len(wv_x4) > 0:
# 周波数データがある時(ピーク検出)
print(wv_x4)
f_pth = d_pth + f_nam + '.csv'
if os.path.exists(f_pth) :
with open(f_pth, 'a') as f :
writer = csv.writer(f)
writer.writerow(wv_x4)
else:
with open(f_pth, 'w') as f :
writer = csv.writer(f)
writer.writerow(wv_x4)
no_idx_cnt = 0
else:
# データがない時
if no_idx_cnt == 0 :
print("<no data>")
no_idx_cnt = no_idx_cnt + 1
pic_ser = pic_ser + 1
pic_pth = d_pth + 'pic2/' + f_nam + '_' + ("000" + str(pic_ser))[-3:] +'.png'
# グラフ表示設定
plt.plot(wv_x2 , wv_y2) # FFT結果
plt.plot(wv_x4 , wv_y4 ,'ro') # ピーク値
plt.title("Feature Value Chart") # タイトル
plt.xlabel("frquency [Hz]") # X軸ラベル
plt.ylabel("amplitude") # Y軸ラベル
plt.xlim(0, 10000) # X軸表示範囲
# plt.ylim(0, 9 * 10 ** 7) # Y軸表示範囲
# plt.xticks(np.arange(0,16001,step=1000),rotation=90) # X軸目盛間隔・向き指定(処理が重くなる感じがするので保留)
plt.minorticks_on() # 補助目盛り表示
plt.grid(which="major", color="black", alpha=0.5) # 目盛り線の表示
plt.grid(which="minor", color="gray", linestyle=":") # 補助目盛り線表示
plt.draw() # リアルタイム更新
if pic_ser < 31 :
plt.savefig(pic_pth) # グラフ画像保存
plt.pause(0.0001) # リアルタイム更新
plt.cla() # 現在軸クリア
if pic_ser > 200 :
print("200回を超えたので、終了します。")
break # データを200回取得したら終了
except KeyboardInterrupt:
print("Ctrl+Cで停止しました")
break
print("Finished")
plt.clf()
plt.close()
# ストリーム終了
stream.stop_stream()
stream.close()
audio.terminate()
着信音検出・判定状況
調査した各着信音の周波数を利用し、どの着信音が鳴っているか判定している状況(動画)です。実際に着信音を鳴らしての判定状況を録画していますが、2倍速再生していることや周囲の雑音が入っているので、着信音は後から追加加工しています。
実際には、着信音が鳴ってから最大2秒程遅れて検出するので、動画ほど早い応答ではありません。
着信音 検出・判定プログラム
マイクから着信音を連続的に受信し、事前調査した各音の特徴的周波数成分の有無によって、着信音を判定します。「着信音 周波数調査用プログラム」と基本同じですが、判定処理を追加しています。
プログラムの行番20 では、予め調べた特徴周波数を配列に格納します。行番28・29では測定ばらつきを考慮し、各周波数の上限・下限を設定します。行番32ー33は着信音の周波数構成を定義しています。例えば、[0,0,0,0,0,1,0,0,0,0,1,0,0] は 行番20の特徴周波数配列 ( ‘f_std’ ) に対応させて、2652[Hz],5302[Hz]が有効な着信音[01] の構成を定義しています。[要素のインデックス+1] が着信音番号になります。
着信音構成(例): [0,0,0,0,0,1,0,0,0,0,1,0,0]
※ f_std (周波数配列)に対応させ、2652[Hz],5302[Hz]が有効な着信音[01] 構成を定義しています。行番95ー97では、検出音声が着信音を構成する各周波数範囲に収まっているか判定し、結果を ‘f_dtect’ に格納します。行番99-100では、判定結果を着信音周波数構成を定義する配列 ‘f_ref’ に照合し、着信音を特定します。
import pyaudio
import wave
import numpy as np
import matplotlib.pyplot as plt
import csv
import os
from scipy.signal import argrelmax
frm_dt = pyaudio.paInt16 # 16-bit resolution
chnl = 1 # 1 channel
s_rate = 44100 # 44.1kHz サンプリング周波数
N = 100 # chunk / s_rate = samp_time (sec)
chunk = 1024 * N # 2^12 一回の取得データ数 (1024*50/44100= 1.16 (sec), 1024*100/44100= 2.32 (sec))
dev_idx = 5 # デバイス番号(必須ではない?(優先度指定している為?))
no_idx_cnt = 0 # データ無し回数
# 音声周波数検出基準情報
f_std = np.array([401,697,881,986,1233,2652,2850,2963,3456,4349,5302,5685,5993]) # 基準周波数
flg_test = False
if flg_test :
f_mgn = np.array([200]*len(f_std)) # ◆TEST用(許容幅を大きくし、意図的に検出させる)
else :
f_mgn = np.array([10]*len(f_std)) # 許容値(基準周波数に対する許容誤差)
f_low = f_std - f_mgn # 各基準周波数要素の下限
f_hgh = f_std + f_mgn # 各基準周波数要素の上限
# 音声一致確認用マスター
f_ref = np.array([[0,0,0,0,0,1,0,0,0,0,1,0,0],
[0,0,0,0,0,0,1,0,0,0,0,1,0],
[0,0,0,0,0,0,1,0,0,0,0,1,0],
[0,0,0,0,0,0,0,0,1,1,0,0,1],
[0,0,0,1,1,0,0,1,0,0,0,0,0],
[0,1,1,0,0,0,0,0,0,0,0,0,0],
[0,1,1,0,0,0,0,0,0,0,0,0,0],
[1,0,0,0,0,0,0,0,0,0,0,0,0]])
audio = pyaudio.PyAudio() # create pyaudio instantiation
# ストリーム作成
stream = audio.open(format = frm_dt , rate = s_rate , channels = chnl, input_device_index = dev_idx , \
input = True , frames_per_buffer = chunk )
# x軸( frquency )
wv_x1 = np.linspace(0, s_rate, chunk)
chnk_lmt = int(chunk/2) # FFT有効範囲考慮
wv_x2 = wv_x1[0:chnk_lmt]
print("Started")
# 音声取得/FFT処理
while True:
try:
# 音声データ取得
data = stream.read(chunk , exception_on_overflow=False )
ndarray = np.frombuffer(data, dtype='int16')
# y軸(FFT : amplitude)
wv_y1 = np.fft.fft(ndarray)
wv_y1 = np.abs(wv_y1)
wv_y2 = wv_y1[0:chnk_lmt]
peak_args = argrelmax(wv_y2,order=200) # ピーク検出(argrelmax:極大値インデックス ,order:次極大値判定範囲/間隔(最小:int 1))
# peak_args(index) >降順sort> peak_args_sort(index)に格納 # ◆未使用(参考)◆
f_peak = wv_y2[peak_args] # インデックスを強度値に変換
f_peak_argsort = f_peak.argsort()[::-1] # 強度降順並替(argsort:値昇順ソート(インデックス返す),[::-1]降順ソート時)
peak_args_sort = peak_args[0][f_peak_argsort] # 強度降順並替後のインデックス配列を指定し、強度降順配列を取得
# 検出ピークの対象を絞り込む
wv_x3 = wv_x2[peak_args]
wv_y3 = wv_y2[peak_args]
if flg_test :
idx_1 = np.where((wv_y3 > 2 * 10**6) & (wv_x3 < 500) & (wv_x3 > 50)) # ◆TEST用(許容幅を大きくし、意図的に検出させる)
idx_2 = np.where((wv_y3 > 1 * 10**6) & (wv_x3 >= 500)) # ◆TEST用(許容幅を大きくし、意図的に検出させる)
else :
idx_1 = np.where((wv_y3 > 5 * 10**7) & (wv_x3 < 500) & (wv_x3 > 200)) # 振幅下限設定(250〜500Hz)
idx_2 = np.where((wv_y3 > 10* 10**6) & (wv_x3 >= 500)) # 振幅下限設定(500Hz〜)
idx_3 = np.append(idx_1, idx_2) # 配列要素統合
wv_x4 = wv_x3[idx_3]
wv_y4 = wv_y3[idx_3]
#print(wv_x4)
# ピークデータ検出時、判定処理
phone_no = ""
if len(wv_x4) > 0:
# 周波数データがある時(ピーク検出)
# 検出周波数が、音声要素周波数範囲内か評価(1:範囲内、0:範囲外)
f_dtect = np.array([0]*len(f_std))
for num in range(len(f_std)):
f_dtect[num] = np.where(np.sum(np.where((f_low[num] < wv_x4) & (wv_x4 < f_hgh[num]) , 1 , 0)) > 0 , 1 , 0)
rtn_ary = np.sum(f_ref * f_dtect - f_ref , axis=1) #
rtn_idx = np.where(rtn_ary == 0)
for num in range(len(rtn_idx[0])):
phone_no = phone_no + "[" + ("00" + str(rtn_idx[0][num] + 1))[-2:] + "]"
# 最終判定結果出力
if phone_no != "" :
msg = phone_no + " is detected."
print(msg)
no_idx_cnt = 0
elif no_idx_cnt == 0 :
msg = "No phone is detected."
print(msg)
no_idx_cnt = 1
# グラフ表示データ設定
plt.plot(wv_x2 , wv_y2) # FFT結果
plt.plot(wv_x4 , wv_y4 ,'ro') # ピーク値
# タイトル(判定結果表示)
if no_idx_cnt == 0 :
plt.title(msg , fontsize=22 , color='red')
else :
plt.title(msg , fontsize=16 , color='black')
plt.xlabel("frquency [Hz]") # X軸ラベル
plt.ylabel("amplitude") # Y軸ラベル
plt.xlim(0, 10000) # X軸表示範囲
#plt.ylim(0, 2 * 10 ** 8) # Y軸表示範囲
plt.minorticks_on() # 補助目盛り表示
plt.grid(which="major", color="black", alpha=0.5) # 目盛り線の表示
plt.grid(which="minor", color="gray", linestyle=":") # 補助目盛り線表示
plt.draw() # リアルタイム更新
plt.pause(0.0001) # リアルタイム更新
plt.cla() # 現在軸クリア
except KeyboardInterrupt:
print("Ctrl+Cで停止しました")
break
print("Finished")
plt.clf()
plt.close()
# ストリーム終了
stream.stop_stream()
stream.close()
audio.terminate()
まとめ
比較的 静かな環境であれば、今回の方法は有効です。騒がしい場所では雑音の影響は大きいと思います。
ただ、USBマイクとラズパイで、音の周波数成分で識別できるとは思っていませんでした。
[資料]「OtoLogic」音声ファイル
今回使用した音声ファイルです。「OtoLogic」というサイトの電話着信音を使用させて頂きました。【 】の中の番号が音声番号と一致しています。
「OtoLogic」https://otologic.jp/free/se/phone02.html