
概要
先回投稿で、ラズパイ4で 「Julius(ジュリアス)」というフリーの音声認識エンジンの “demo モード” を体験しました。
今回は、“module モード” で起動し、python プログラムからのデータ取得を試みました。
( Julius公式サイト : https://julius.osdn.jp/index.php )
Julius module モード実行
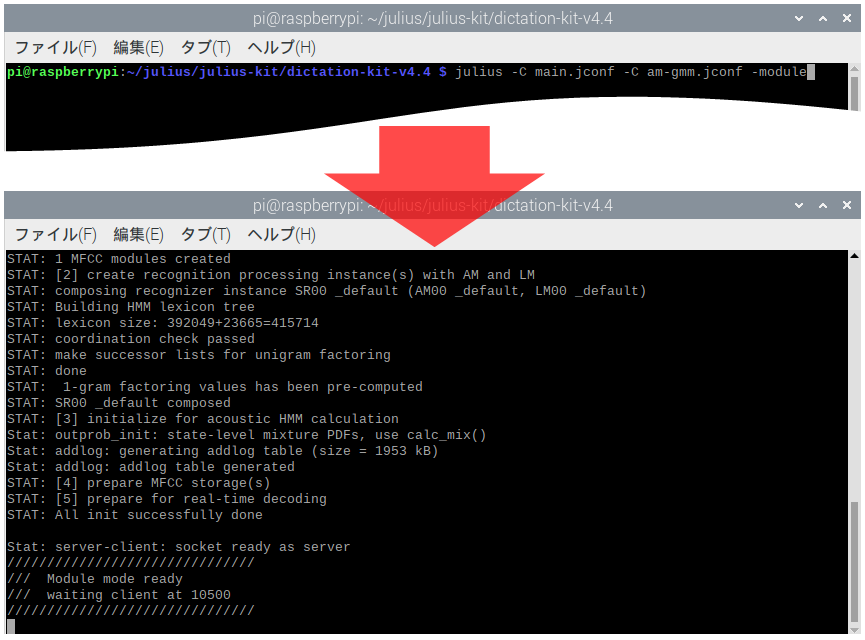
module モードでの実行は、特に問題は無かった様です。
オプション “-demo” を “-module” に変えて実行します。
# ディレクトリを変更する
cd ~/julius/julius-kit/dictation-kit-v4.4
# Julius モジュール(module)モードで実行する
julius -C main.jconf -C am-gmm.jconf -module次の図は、“module モード” で起動した状態です。
python プログラム処理概略
クライアントは音声認識結果をソケット通信で Julius サーバーから、XML 形式テキストメッセージを取得できます。
python プログラムは、次の形式データを取得・分析します。
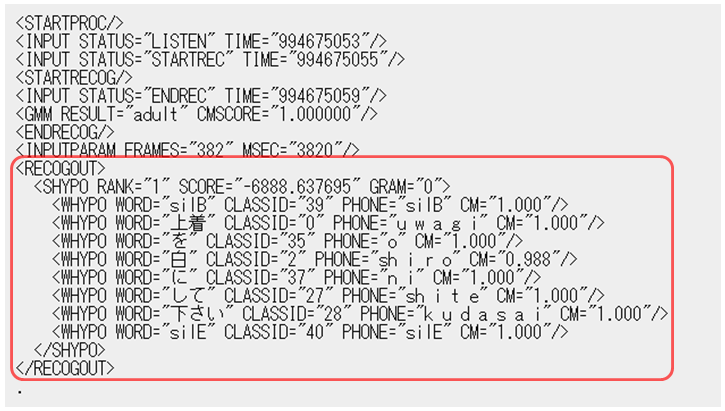
<SCORE>:音声認識エンジンの出した尤度
<WORD>:認識結果の単語表記
<CLASSID>:言語エントリ(N-gram単語エントリ、または文法カテゴリ番号)
<PHONE>:音素列 <CM>:単語確信度
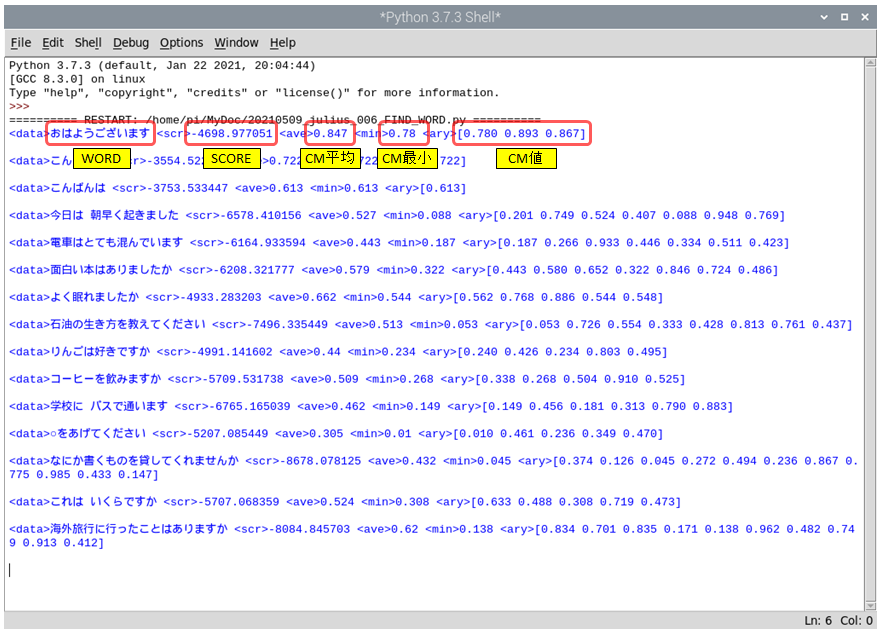
次図では 取得データを 単語(or 短文)、及び <SCORE>値 , <CM>値を抽出し、 <CM>値の平均・最小を計算・出力しています。
<SCORE>値 , <CM>値の平均・最小は、認識結果良否判定に利用するつもりでしたが、同環境・同条件で話したつもりでも値にばらつきがあり、簡単ではなさそうです。
また、周囲で他の人が ちょっとした作業をしている時なども、 少なからず影響を受けると感じました。
プログラム概要
クライアントは Juliusサーバーからソケット通信で、認識結果を取得します。ソケット通信に関するコードは下記表の通りです。今回の場合、クライント(pythonプログラム)もJuliusサーバーも同じなのですが、同じ様に処理できました。
通信サーバーにホスト名を設定していますが、IPアドレスを設定すればネットワーク経由でデータ取得できるのだと思います。いずれ機会があれば試してみようと思います。
| 行番 | 内 容 |
| 5〜7 | 通信サーバー、ポート、受信データサイズ設定 |
| 11〜13 | 通信サーバー接続確立処理 |
| 72 | データ受信 ※ ’ </RECOGOUT>\n ’ 受信まで |
| 75〜78 | 接続異常処理 |
| 85〜86 | 通信サーバー接続切断処理 |
取得データの解析は、行番 20 〜 70 で処理しています。
行番20でデータ末の ’ </RECOGOUT>\n ’ を検出後、分析を開始します。行番27でデータを分割し、1行づつ処理します。
今回データ取得する行には、'<WHYPO ‘,'<SHYPO ‘ の文字を含みます。行番30・53で検出後、各行の ‘SCORE=’ , ‘WORD=’ , ‘CM=’ 等の位置から、それぞれ必要情報を取得します。
import socket
import time
import sys
HOST = 'raspberrypi' # juliusサーバーホスト(IPアドレス)
PORT = 10500 # juliusサーバーの待ち受けポート
DATESIZE = 1024 # 受信データバイト数
s_Word =['WORD' , 'CLASSID' , 'PHONE' , 'CM'] # 検索ワード
try:
# socket通信でjuliusサーバー接続
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((HOST, PORT))
gData = "" # サーバーから取得した全データ
# メインループ
while True:
if '</RECOGOUT>\n' in gData : # データ区切(最終)判定 >>> 取得データ解析
gWord = "" # 取得した言葉を格納
g_CM = "" # 単語信頼度
gCM_Ary = [] # 単語信頼度格納配列
g_Score = '' # 対数尤度(音響スコア+言語スコア)
# 取得データを一行づつ分析
for gLine in gData.split('\n') : # 取得データを改行コードで分割
gWrd_Inf = [] # 一時データ格納用配列
if gLine.find('<WHYPO ') != -1: # 分割行単位でデータ評価
for s_wrd in s_Word : # 'WORD','CLASSID','PHONE','CM' のデータ検索(ループ処理)
wTmp=""
index = gLine.find( s_wrd + '="' ) # 対象データ有無確認
if index != -1:
idx_s = index + len(s_wrd + '="' ) # 対象データ先頭位置確認
idx_e = gLine.find('"' , idx_s ) # 対象データ最終位置確認
wTmp = gLine[ idx_s : idx_e ] # 対象データ抽出
gWrd_Inf.append(wTmp) # 一時データ格納用配列データ追加
# 無音モデル非表示(silB:文頭,silE:文末,sp:単語間)
if gWrd_Inf[2] != "silB" and gWrd_Inf[2] != "silE" and gWrd_Inf[2] != "sp" :
gWord = gWord + gWrd_Inf[0]
gCM_Ary.append(float(gWrd_Inf[3]))
g_CM = g_CM + gWrd_Inf[3] + " "
# print(gWrd_Inf[0]+","+gWrd_Inf[1]+","+gWrd_Inf[2]+","+gWrd_Inf[3]+","+gLine) # データ確認時にコメント解除
elif gWrd_Inf[2] == "sp" :
gWord = gWord + " "
elif gLine.find('<SHYPO ') != -1 :
s_tmp = 'SCORE="'
index = gLine.find( s_tmp ) # 対象データ有無確認
if index != -1:
idx_s = index + len(s_tmp) # 対象データ先頭位置確認
idx_e = gLine.find('"' , idx_s ) # 対象データ最終位置確認
gScore = gLine[ idx_s : idx_e ] # 対象データ抽出
# データ分析結果表示(有効データ未確認時、表示しない)
if gWord.strip() != "" and len(gCM_Ary) > 0 and gScore != "" :
gCM_Ave = round(sum(gCM_Ary) / len(gCM_Ary) , 3 ) # 確信度の平均値計算
#if gCM_Ave == 1 and min(gCM_Ary) == 1 and float(gScore) < -3000 :
print("<data>" + gWord + " <scr>" + gScore + " <ave>" + str(gCM_Ave) + " <min>" + str(min(gCM_Ary)) + " <ary>[" + g_CM.strip() + "]")
#print("")
gData = "" # 受信データ初期化
else :
gData = gData + sock.recv(DATESIZE).decode('utf-8') # データ区切(最終)検出まで、データ追加受信
# サーバー接続失敗
except socket.error :
print("Error : Server Connection Failed")
sys.exit()
# 終了処理
except KeyboardInterrupt :
print("Program End")
print("")
sock.send("DIE".encode('utf-8'))
sock.close()
独自辞書作成
Julius はユーザーが作成した独自辞書を使用し、音声認識できるので、インターネット上の例を参考にして試しました。登録語句が少ないので単純に認識率が上がると思いましたが、雑音にも反応しいずれかの語句が選択されるので、状況によっては返って悪化する印象を受けました。
一方、登録語句、語句の組み合わせ等を検討し、<CM>値(確信度)等による判定ロジックを追加すれば、音声コマンドによる簡単なアプリケーション操作は出来る様な印象を持ちました。
簡単に作成手順を記載します。
まず、ルートディレクトリ下 “~/julius/” に移動し、ディレクトリを作成しました。ディレクトリ名、ファイル名は特に決まりは無い(?)ようです。今回は、“dict_group_work” としました。
cd julius
mkdir dict_group_work 作成ディレクトリ下に拡張子が異なる7ファイル作成します。
各ファイル機能・正しい作成方法は理解していません。インターネット等を検索しながら、VIMエディタ等で作成・編集します。
今回ファイル名は “GroupWork” としました。
① GroupWork.yomi
今回は次の通り4語句(4行)登録しました。各行に同じ語句を半角スペースを挟んで2回書いています。サイトによっては、TAB区切りにするとか、1回目の方は漢字で書く例がありました。いずれも動作は確認出来ました。
また、今回の場合、「みぎ」「むけ」「ひだり」「まわれ」「もとにもどれ」の様に重複部分を分け、登録するのが正しい様ですが、音声認識すると安定するので、次の様にしています。
みぎむけみぎ みぎむけみぎ
ひだりむけひだり ひだりむけひだり
まわれみぎ まわれみぎ
もとにもどれ もとにもどれ② GroupWork.phone
“GroupWork.yomi” 作成後、次コマンドを実行します。
iconv -f utf8 -t eucjp ~/julius/dict_group_work/GroupWork.yomi | ~/julius/julius-4.4.2.1/gramtools/yomi2voca/yomi2voca.pl | iconv -f eucjp -t utf8 > ~/julius/dict_group_work/GroupWork.phone次のファイルが作成されます。
みぎむけみぎ m i g i m u k e m i g i
ひだりむけひだり h i d a r i m u k e h i d a r i
まわれみぎ m a w a r e m i g i
もとにもどれ m o t o n i m o d o r e③ GroupWork.grammar
インターネット上の例を参考に同じ感じで作成してみました。
S:NS_B GROUP NS_E
GROUP : MIGIMUKEMIGI
GROUP : HIDARIMUKEHIDARI
GROUP : MAWAREMIGI
GROUP : MOTONIMODORE④ GroupWork.voca
こちらも見よう見まねで作成しました。
% MIGIMUKEMIGI
みぎむけみぎ m i g i m u k e m i g i
% HIDARIMUKEHIDARI
ひだりむけひだり h i d a r i m u k e h i d a r i
% MAWAREMIGI
まわれみぎ m a w a r e m i g i
% MOTONIMODORE
もとにもどれ m o t o n i m o d o r e
% NS_B
[s] silB
% NS_E
[/s] silE⑤ GroupWork.dfa
⑥ GroupWork.term
⑦ GroupWork.dict
次コマンドを実行すると3ファイルが同時に生成されます。
cd ~/julius/julius-4.4.2.1/gramtools/mkdfa
mkdfa.pl ~/julius/dict_group_work/GroupWork
独自辞書による Julius 実行
下記のコマンドにて、独自辞書による Julius を modue モードで実行します。 python プログラムは同じものを使えます。
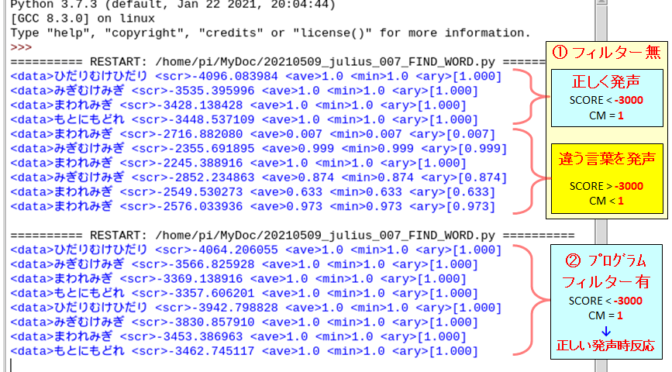
julius -C ~/julius/julius-kit/dictation-kit-v4.4/am-gmm.jconf -nostrip -gram ~/julius/dict_group_work/GroupWork -input mic -module 次の図は、独自辞書を使って Julius を実行し、python プログラム側で認識結果を取得・分析している状況です。プログラムは、①フィルター無 と ②フィルター有 の2回に分けて実行しています。
フィルターとは プログラム行番 65 の i f 文(条件分岐)のことです。①フィルター無 の場合、現状記載通り条件文はコメントアウトされ、そのまま認識結果を出力します。 一方、②フィルター有 の場合は、コメントを外し条件が成立した場合のみ、認識結果を出力するようにします。
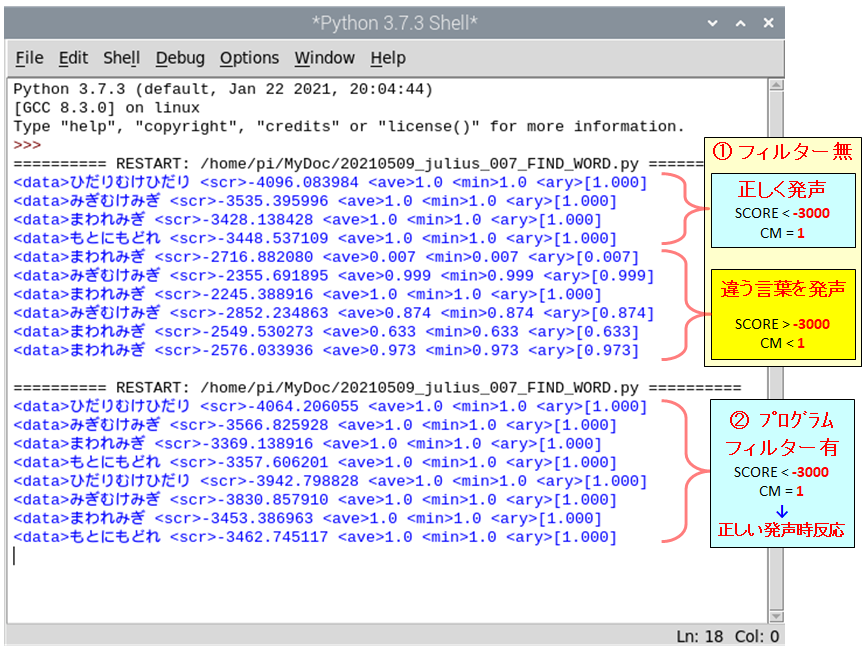
上図の①フィルター無 の場合、違う言葉を発声した場合も 登録語句のいずれかに判定しています。 但し、正しく発生した時の<SCORE>値はー3000未満、<CM>値は1となります。一方、違う言葉を発声した時、<SCORE>値はー3000以上、<CM>値は1未満となっていることを確認しました。
この様な結果を条件にして、②フィルター有 のプログラムを実行することで、大幅に誤判定を削減することが出来ました。
まとめ
Julius の初歩的な使い方を学びました。
登録語句を限定した独自辞書利用 と pyrhonプログラム側でフィルターすることで、音声コマンドによる簡単なアプリケーション操作は出来そうな感触は持てました。
一方、限定的な利用にて、“大幅に誤判定を削減出来た” と書いたものの、似ても似つかない騒音にも反応してしまうことがあります。私には原因究明と対策は不可能、と諦めていますが。