
概要
過去投稿で「Julius」という音声認識エンジンを使い、幾つかの日本語語句を検出する実験をしています。
今回は音声の周波数成分の中で最も強いピークを検出するプログラムを作成してみました。素人なのでよくわかっていませんが、例えばブザー、電話着信音、自動車クラクション など、様々な音声はそれぞれ特有の周波数成分で構成されていて、周波数成分分析により、特定音声の検出に利用できると理解しています。
結果(グラフ出力)
次動画は、今回作成したプログラム出力状況です。連続的に音声を取得し、周波数成分(グラフ)表示します。同時に最も強い周波数成分を検出し、グラフ上・中央に表示しています。
途中でウィンドウ中央に “音声 261Hz” の様に表示されますが、これは後から編集したものです。正しく検出されているか 確認する為に、別パソコンで周波数を設定し鳴らした音を検出しています。プログラムは、NumPy・SciPy など、なんとなく理解しながら編集しましたが、とりあえず正しく検出されている様です。
グラフがコマ送りの様ですが、音声を 2.32 秒毎に取り込んで処理している為です。
今回使用マイクは次のものです。WEBカメラ内蔵マイクでも今のところ特に問題はないのですが、専用化したいという気持ちが高まり購入しました。
音声解析結果の確認
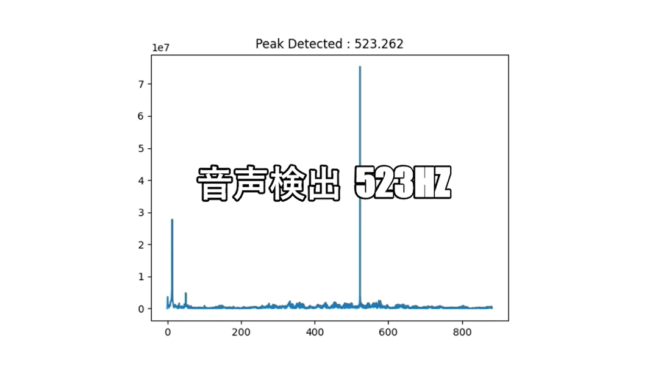
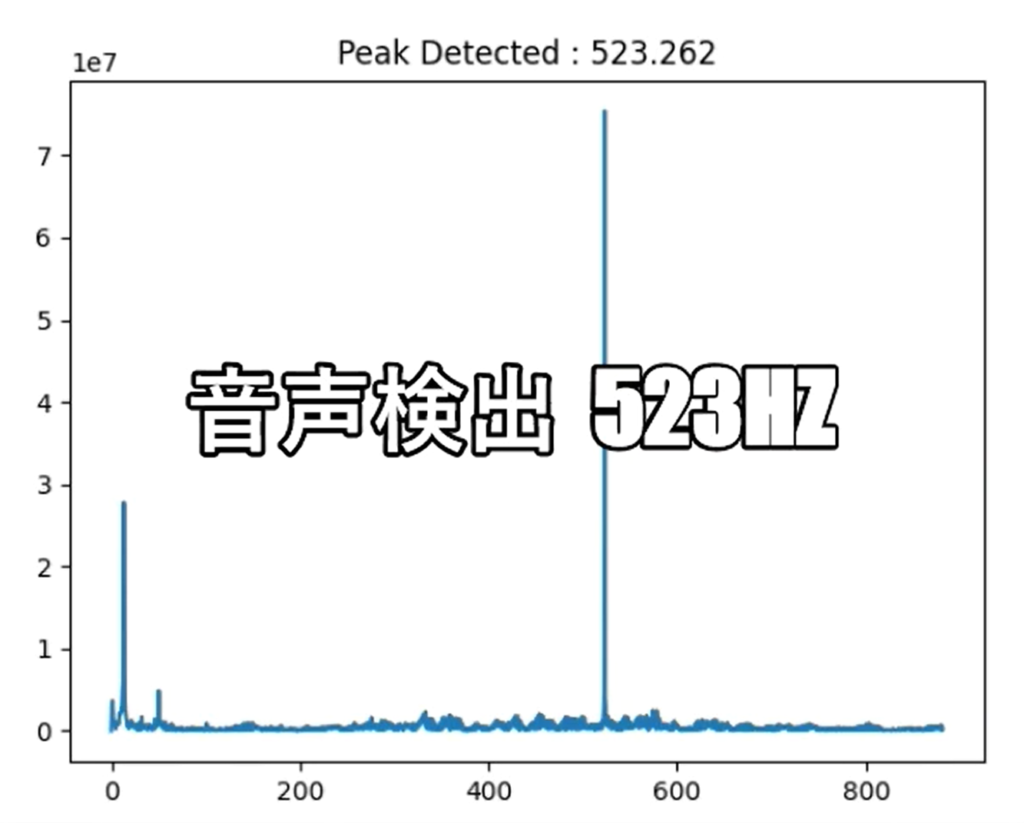
別のパソコンで周波数を設定して鳴らした音を検出しています。今回は、“261.626Hz”、“391.995Hz”、“523.251Hz” の3つの周波数の音について確認し、正しく検出されていることを確認しました。
参考までに音階(?)と周波数の関係を次表に示します。今回、確認周波数は、[ド]、[ソ]、[ド]に相当します。
| ド | レ | ミ | ファ | ソ | ラ | シ | ド |
| 261.626 | 293.665 | 329.628 | 349.228 | 391.995 | 440.000 | 493.883 | 523.251 |
検出状況①②③の通り、正しく検出できた様です。
【 特定周波数の検出状況① 261 Hz 】
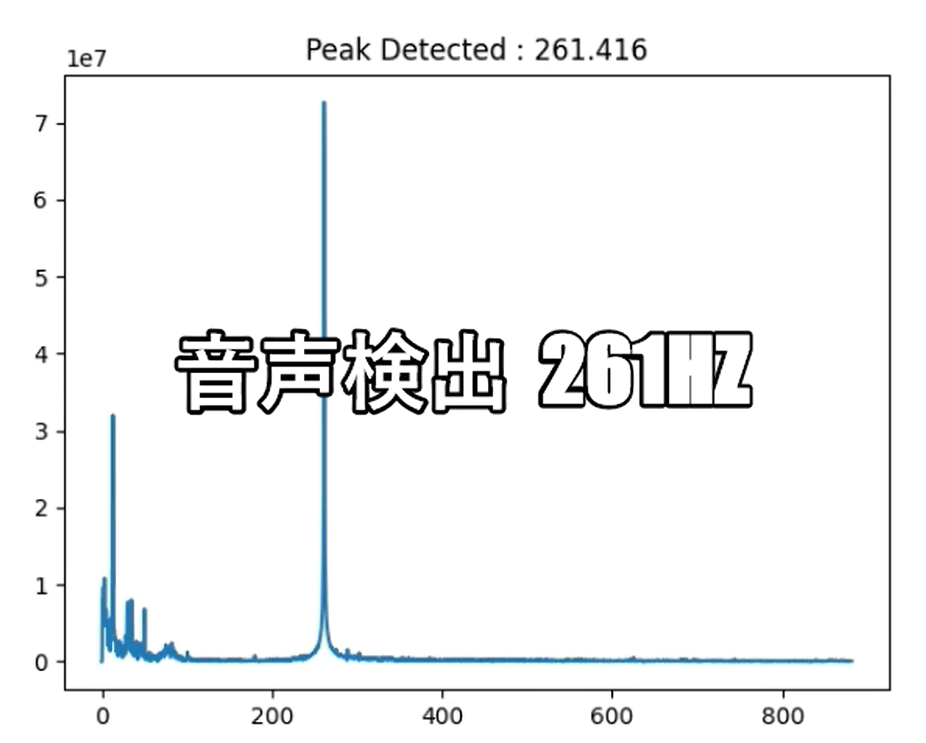
【 特定周波数の検出状況② 391 Hz 】
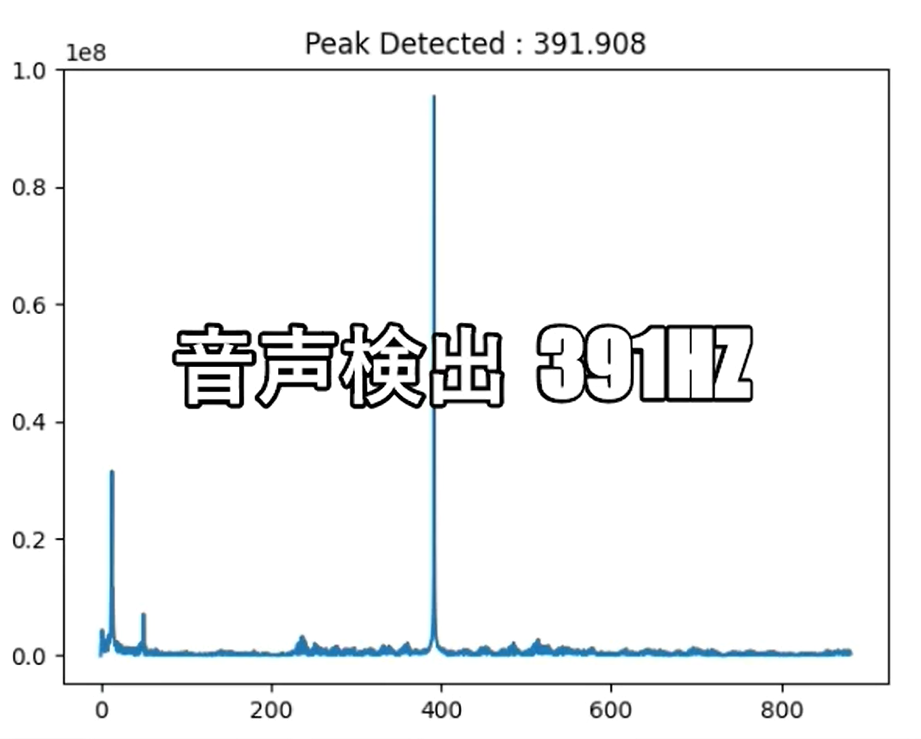
【 特定周波数の検出状況③ 523 Hz 】
プログラム
① 確認用音声発生プログラム (別パソコン)
行番4で「ド・レ・ミ・ファ・ソ・ラ・シ・ド」相当の周波数を定義し、行番8でインデックスを変えて、周波数変更後プログラムを実行します。音発生時間は行番9で定義します。
import pyaudio
import numpy as np
SND_FRQ= [ 261.626 , 293.665 , 329.628 , 349.228 , 391.995 , 440.000 , 493.883 , 523.251 ]
RATE = 44100 # サンプリングレート
sndFrq = SND_FRQ[0] # 周波数設定
t_Beep = 6 # 処理時間
# 出力ストリーム
p = pyaudio.PyAudio()
stream = p.open(format=pyaudio.paFloat32 , channels=1 , rate=RATE , frames_per_buffer=1024 , output=True)
tone = np.sin(np.arange(int(t_Beep * RATE)) * (float(sndFrq) * np.pi * 2 / RATE))
stream.write(tone.astype(np.float32).tobytes())
stream.close() 音声発声プログラムは、Windows10パソコンにインストールしたpython3.8 で動かしています。“PyAudio” が、うまくインストールできなかったので、一旦ダウンロード後、ローカル環境でインストールしています。私の環境では特に問題は無いようですが、利用される場合は自己責任でお願い致します。
[参考] https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyaudio
py -m pip install PyAudio-0.2.11-cp38-cp38-win_amd64.whl
② 音声解析プログラム
理解の過程で調べたことなどはコメントに記載しています。
import pyaudio
import wave
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import argrelmax
frm_dt = pyaudio.paInt16 # 16-bit resolution
chnl = 1 # 1 channel
s_rate = 44100 # 44.1kHz サンプリング周波数
N = 100 # chunk / s_rate = samp_time (sec)
chunk = 1024 * N # 2^12 一回の取得データ数 (1024*50/44100= 1.16 (sec), 1024*100/44100= 2.32 (sec))
dev_idx = 5 # デバイス番号(必須ではない?(優先度指定している為?))
audio = pyaudio.PyAudio() # create pyaudio instantiation
# ストリームの作成
stream = audio.open(format = frm_dt , rate = s_rate , channels = chnl, input_device_index = dev_idx , \
input = True , frames_per_buffer = chunk )
# x軸
wv_x1 = np.linspace(0, s_rate, chunk)
chnk_lmt = int(chunk/50) # ■ X軸幅調整
wv_x2 = wv_x1[0:chnk_lmt]
print("Started")
# 音声取得/FFT処理
while True:
try:
# 音声データ取得
data = stream.read(chunk , exception_on_overflow=False )
ndarray = np.frombuffer(data, dtype='int16')
# FFT
wv_y1 = np.fft.fft(ndarray)
wv_y1 = np.abs(wv_y1)
wv_y1[0] = 0
wv_y2 = wv_y1[0:chnk_lmt]
peak_args = argrelmax(wv_y2,order=500) # ピーク検出(argrelmax:極大値インデックス ,order:次極大値判定範囲/間隔(最小:int 1))
f_peak = wv_y2[peak_args] # インデックスを強度値に変換
f_peak_argsort = f_peak.argsort()[::-1] # 強度降順並替(argsort:値昇順ソート(インデックス返す),[::-1]降順ソート時)
peak_args_sort = peak_args[0][f_peak_argsort] # 強度降順並替後のインデックス配列を指定し、強度降順配列を取得
frq_tmp = wv_x2[peak_args_sort[0]]
frq_str = str(round(1000*frq_tmp)/1000)
# リアルタイムにグラフ表示
plt.plot(wv_x2 , wv_y2)
plt.title("Peak Detected : " + frq_str)
plt.draw()
plt.pause(0.0001)
plt.cla()
feature = np.where((wv_y2 > 0.5*1e7) & (wv_x2 > 45)) # wv_x2:対象周波数域,wv_y2:周波数の強度(?)
frq_ary = feature[0] * (s_rate / chunk) # 指定強度以上の周波数抽出・出力
frq_ary = np.round(10*frq_ary) # 小数点1桁以下四捨五入
print( frq_ary )
except KeyboardInterrupt:
print("Ctrl+Cで停止しました")
break
print("Finished")
# ストリームの終了
stream.stop_stream()
stream.close()
audio.terminate()サンプリング周波数やグラフ周波数軸の考え方等がよくわからなかったので、次表の様なことも調べました。
| フーリエ 変換 | 元の波形を sin関数に分類し、各sin波の振幅を周波数毎にまとめる処理。 |
| FFT | 高速フーリエ変換(Fast Fourier Transform)離散フーリエ変換を計算機上で高速計算するアルゴリズム。 |
| 標本化 | 連続関数の点の値を標本として離散関数変換処理。 |
| 標本化 定理 | 時系列データに含まれる最大周波数の2倍を超えた周波数で標本化(サンプリング)すれば完全に元の波形に再構成される。ナイキスト周波数はサンプリング周波数の1/2の周波数のこと。サンプリング周波数 44100Hzの場合、22050Hzとなり FFTで正しく検出できる最大の周波数となる。 人間聴覚:20Hz〜20KHz → サンプリング:40KHz以上 (音声認識の場合:〜8KHz程度) |
| 折り返し雑音 | ナイキスト周波数を超える周波数成分を含む信号が入力された場合、エイリアス(偽信号)として検出。元の信号とエイリアスが重なって生じる歪のこと。 |
| 周波数軸 (横軸) | f [n] = ( fs * n ) ÷ N (n=0 , ・・・ , N-1) N : FFTポイント数,fs : サンプリング周波数,n : 配列インデックス |
| 分解能 | スペクトル周波数分解能:1/[時間窓長(sec)] Hz ※時間窓長1sec 時分解能:1Hz ※時間窓長10sec時分解能: 0.1Hz 時間窓を長くすると分解能は上がるが、応答は鈍い。 |
まとめ
よく理解出来ていませんが、処理の流れは少し理解できました。発声音と計測の同期など課題があることを認識しました。一方で簡単なコマンドでFFT処理できるなんて驚きです。